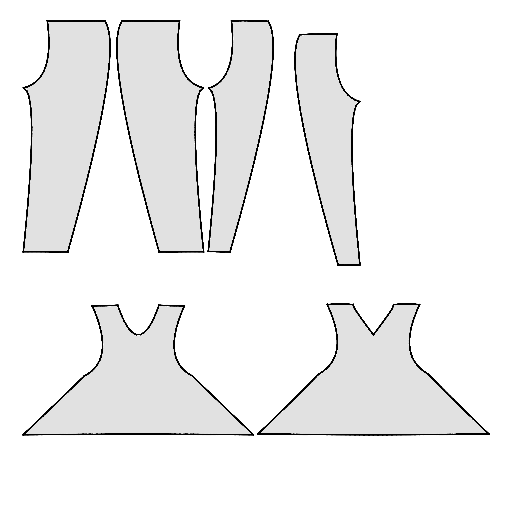
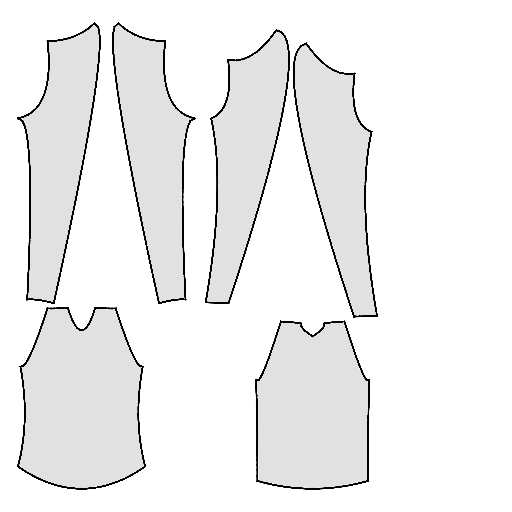
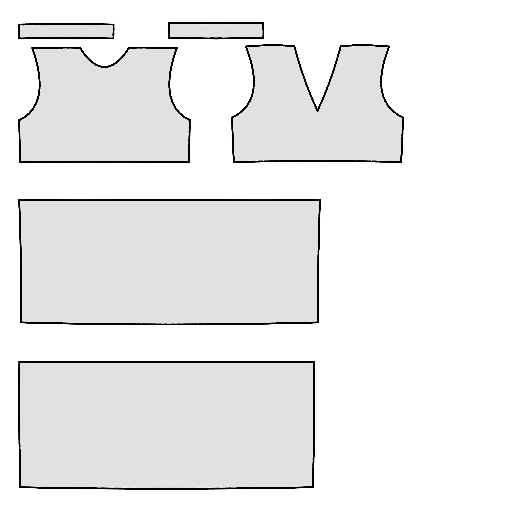
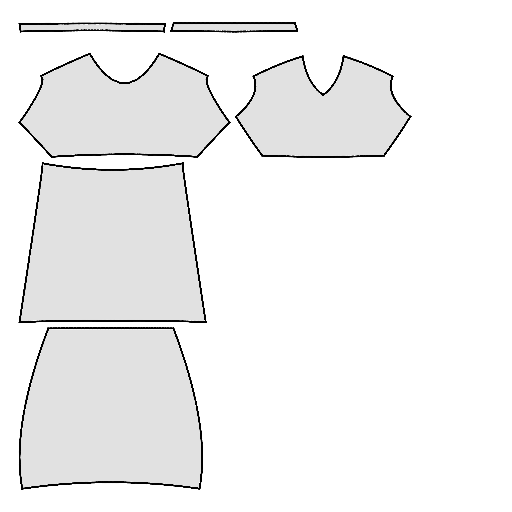
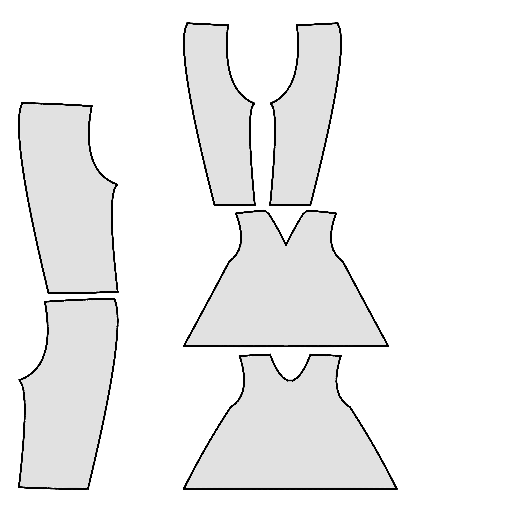
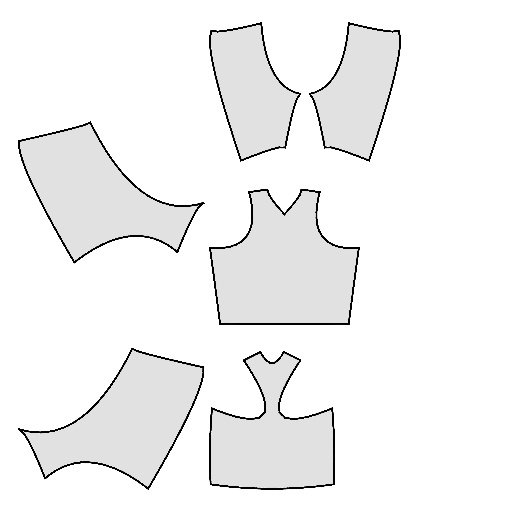
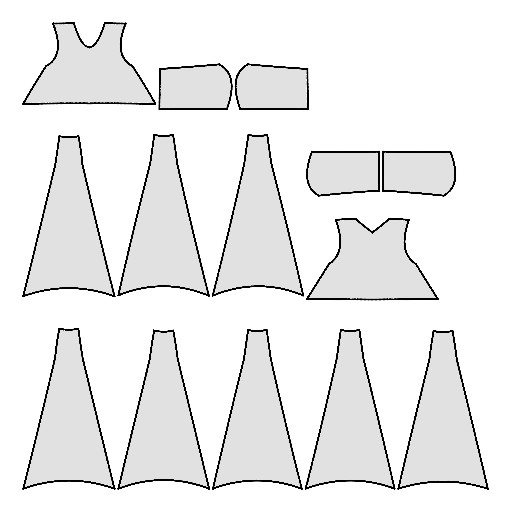
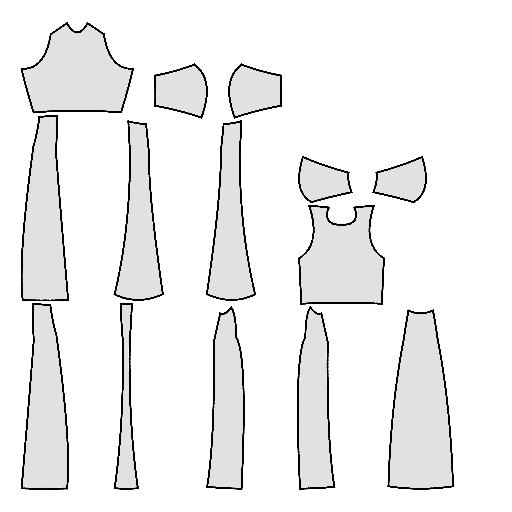
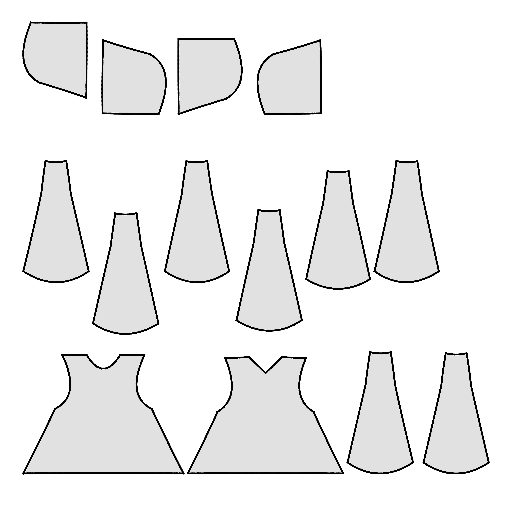
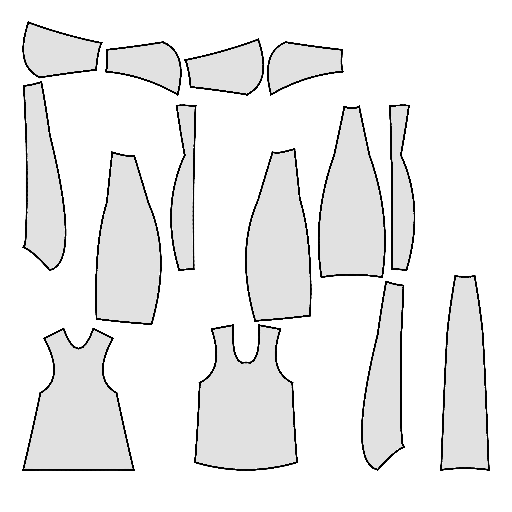
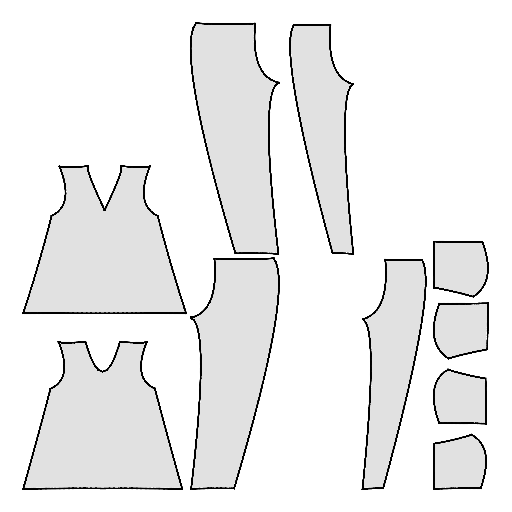
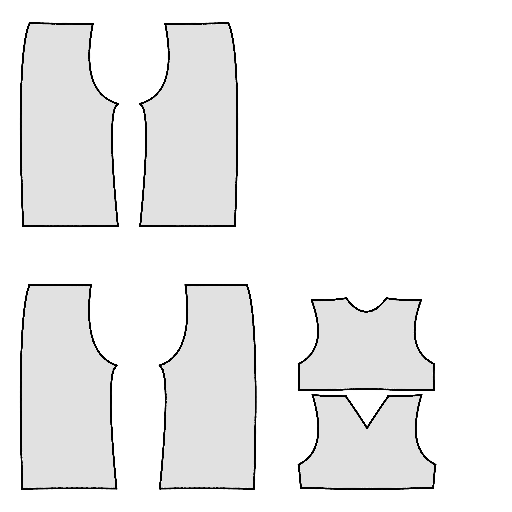
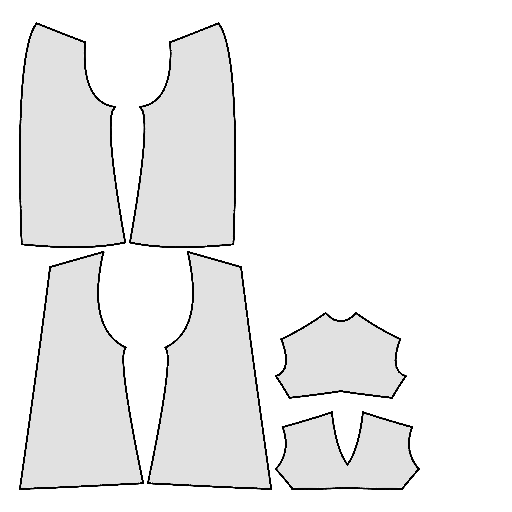
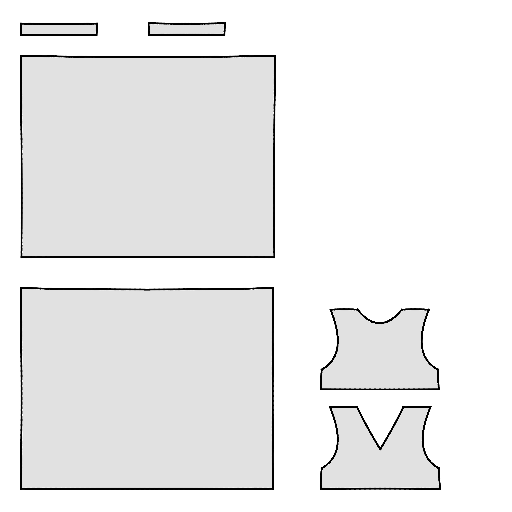
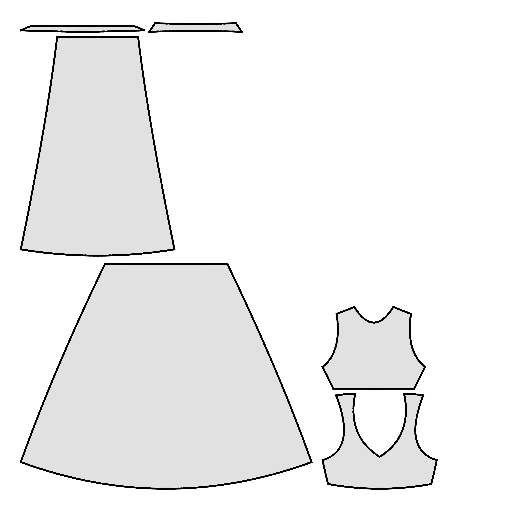
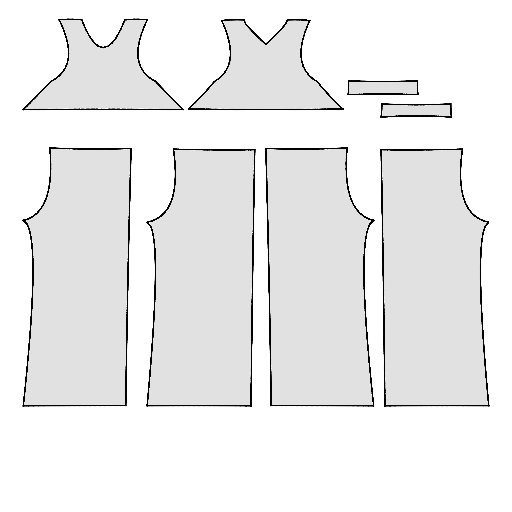
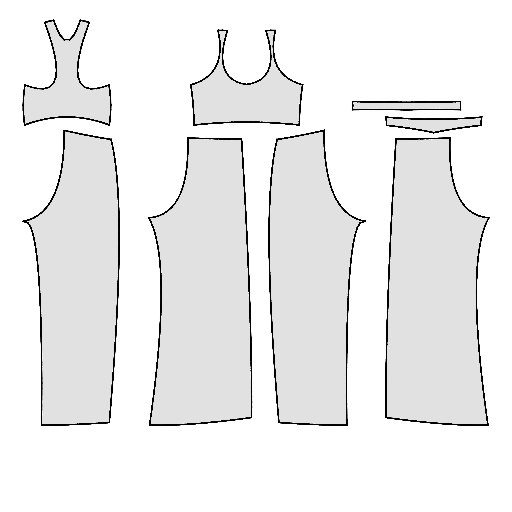
Pipeline
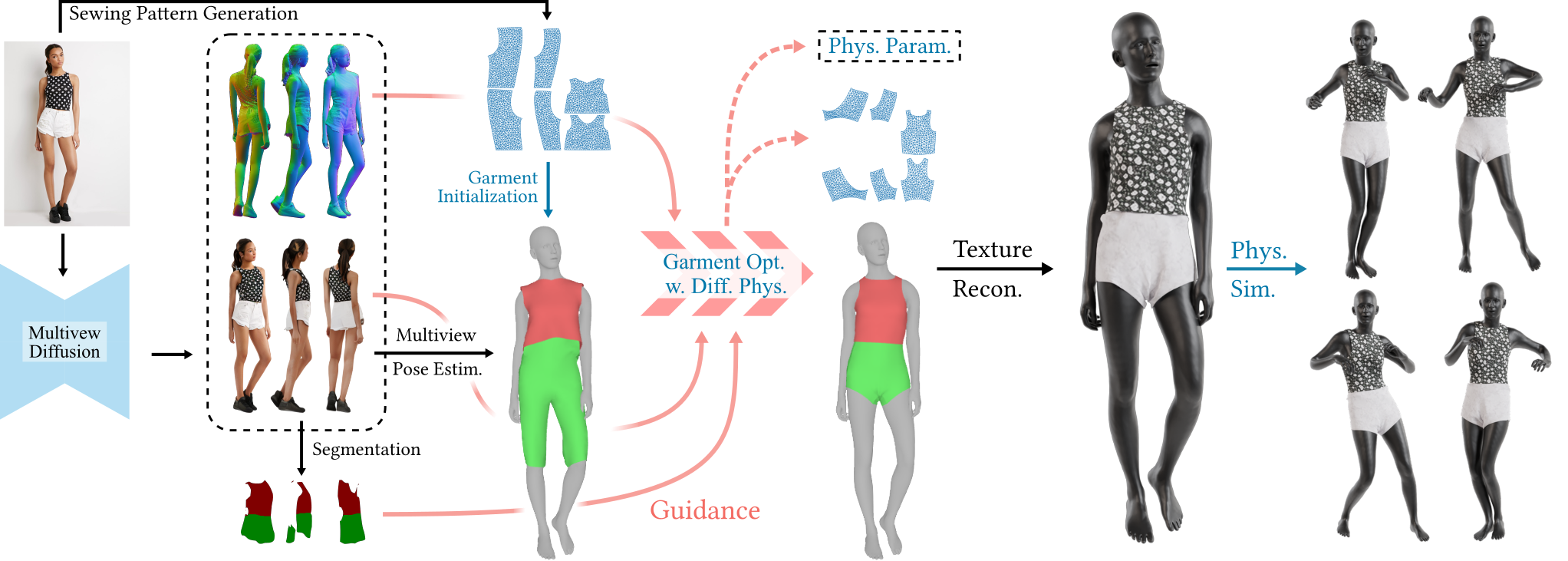
Starting with a single-view input image of a clothed human, we first derive an initial estimation of the sewing pattern. Additionally, we employ multi-view diffusion to generate orbital camera views, which serve as ground-truth 3D information for both human pose and garment shape. Next, we utilize differentiable simulation to sew and drape the pattern onto the posed human model, optimizing its shape and physical parameters in conjunction with geometric regularizers. Finally, the optimized garment shape provides a physically plausible rest shape in its static state and is readily animatable using a physical simulator.